
Introduction to Ceph
Architecture Overview
Ceph is an open source, distributed, scaled-out, software-defined storage system. through the use of the Controlled Replication Under Scalable Hashing (CRUSH) algorithm.
Ceph provides three main types of storage:
block storage via the RADOS Block Device (RBD), file storage via CephFS, and object storage via RADOS Gateway, which provides S3 and swift-compatible storage.

How Ceph works
According to the above image The core storage layer in Ceph is the Reliable Autonomous Distributed Object Store (RADOS). The RADOS layer in Ceph consists of the Ceph components (number of Object Storage Daemons (OSDs), and Ceph Monitors (MONs), etc).
Each OSD is completely independent and forms peer-to-peer relationships to form a cluster. Each OSD is typically mapped to a single disk, into a single disk, in contrast to the traditional approach of presenting a number of disks combined into a single device via a RAID controller to the OS.
It serves the data from the hard drive or ingests it and stores it on the drive. The OSD also assures storage redundancy, by replicating data to other OSDs based on the CRUSH map.
When a drive goes down, the OSD will goes down too and the monitor nodes will redistribute an update CRUSH map so the clients are aware and know where to get the data. The OSDs also respond to this update, because redundancy is lost, they may start to replicate non-redundant data to make it redundant again (across fewer nodes).
An algorithm called CRUSH is then used to place the placement groups of each pool onto the OSDs. This reduces the tasks of tracking millions of objects to a matter of tracking a much more manageable number of placement groups, normally measured in thousands.

Your Data →Objects →Pools →placement groups →OSDs
So objects live in a pool and they’re associated with one placement group(each pool contains a number of placement groups). The placement group is associated with the number of OSDs as the replication count.
So:
- Pool contains objects
- Pg: placement group contains objects within a pool
- One object belongs to only one pg
- Pg belongs to multiple OSDs
If a replication count was three, each placement group with be associated with three OSDs. A primary OSD and two secondary OSDs. The primary OSD will serve data and peer with the secondary OSDs for data redundancy. In case the primary OSD goes down, a secondary OSD can be promoted to become the primary to serve data, allowing for high availability..
A monitor or MON node is responsible for helping reach a consensus in distributed decision making using the Paxos protocol. It’s important to keep in mind that the Ceph monitor node does not store or process any metadata. It only keeps track of the CRUSH map for both clients and individual storage nodes.
In Ceph, consistency is favored over availability. A majority of the configured monitors need to be available for the cluster to be functional. For example, if there are two monitors and one fails, only 50% of the monitors are available so the cluster would not function. But if there are three monitors, the cluster would survive one node’s failure and still be fully functional.
As i mentioned, Pools are logical partitions for storing objects.
In Ceph, the objects belong to pools and pools are comprised of placement groups. Each placement group maps to a list of OSDs. This is the critical path you need to understand.

The pool is the way how Ceph divides the global storage. This division or partition is the abstraction used to isolate clients data for each project(easy administration). for example i created pool called Kubernetes and i used it just for data that comes from my Kubernetes cluster.
So how we go from objects to OSDs via pools and placements groups? It is straight.
In Ceph one object will be stored in a concrete pool so the pool identifier (a number) and the name of the object are used to uniquely identify the object in the system.
Those two values, the pool id and the name of the object, are used to get a placement group via hashing.
When a pool is created it is assigned a number of placement groups (PGs). One object is always stored in a concrete pool so the pool identifier (a number) and the name of the object is used to uniquely identify each object in the system.
With the pool identifier and the hashed name of the object, Ceph will compute the hash modulo the number of PGs to retrieve the dynamic list of OSDs.
In detail, the steps to compute for one placement group for the object named ‘tree’ in the pool ‘images’ (pool id 7) with 65536 placement groups would be…
- Hash the object name : hash(‘tree’) = 0xA062B8CF
- Calculates the hash modulo the number of PGs : 0xA062B8CF % 65536 = 0xB8CF
- Get the pool id : ‘images’ = 7
- Prepends the pool id to 0xB8CF to get the placement group: 7.B8CF
Ceph uses this new placement group (7.B8CF) together with the cluster map and the placement rules to get the dynamic list of OSDs…
- CRUSH(‘7.B8CF’) = [4, 19, 3]
The size of this list is the number of replicas configured in the pool. The first OSD in the list is the primary, the next one is the secondary and so on.
RADOS Pools and Client Access
Replicated pools:
Replicated RADOS pools are the default pool type in Ceph; data is received by the primary OSD from the client and then replicated to the remaining OSDs. The logic behind the replication is fairly simple and requires minimal processing to calculate and replicate the data between OSDs. However, as data has to be written multiple times across the OSDs. By Default, Ceph will use a replication factor of 3x, so all data will be written three time; this does not take into account any other write amplification that may be present further down in the Ceph stack. This write penalty has two main drawbacks. It obviously puts further I/O load on your Ceph cluster, as there is more data to be written, and in the case of SSDs, these extra writes will wear out the flash cells more quickly.
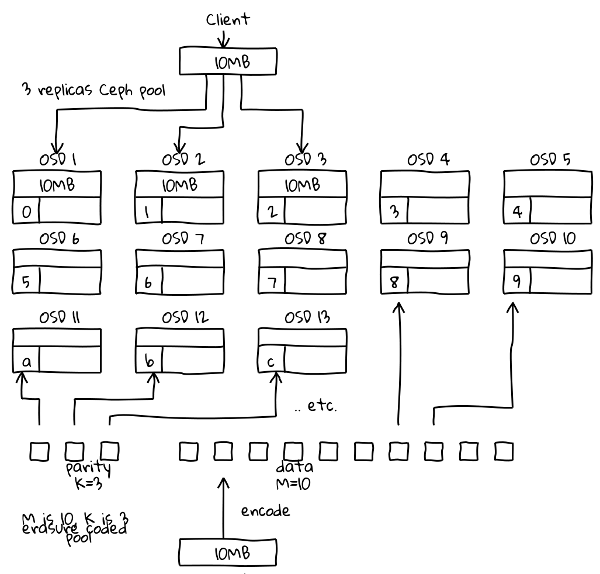
Erasure code pools:
Ceph’s default replication level provides excellent protection against data loss by storing three copies of your data in different OSDs. However, storing three copies of data vastly increase both the purchase cost of the hardware and the associated operational costs, such as power and cooling. Furthermore, storing copies also means that for every client, the backend storage must write three times the amount of data.
Erasure coding allows Ceph to achieve either greater usable storage capacity or increase resilience to disk failure for the same number if disks. Erasure coding achieve this by splitting up the object into a number of parts and then also calculating a type of cyclic redundancy check (CRC), the ensure code, and then storing the results in one or more extra parts. Each part is then stored on a separate OSD. these parts are referred to as K and M chunks, where K refers to the number of data shards and M refer to the number of erasure code shards. As in RAID, these can often be expressed in form K+M, or 4+2, for example. A 3+1 configuration will give you 75% usable capacity but only allows for a single OSD failure, and so would not be recommended. In comparison, a three-way replica pool only gives you 33% usable capacity. 4+2 configurations would give you 66% usable capacity and allows for two OSD failures.
These smaller shards will generate a large amount of small I/O and cause an additional load on some clusters.
Reading back from these high-chunk pools is also a problem. Unlike in a replica pool, where Ceph can read just the requested data from any offset in an object, in an erasure pool, all shards from all OSDs have to be read before read request can be satisfied. In the 18+2 example, this can massively amplify the amount of required disk read ops, and average latency will increase as a result. A 4+2 configuration in some instances will get a performance gain compared to a replica pool, from the result of splitting an object into shards. As data is effectively striped over a number of OSDs, each OSD has to write less data.
Recommendations for implementation Ceph (Optional):
How to plan a successful Ceph implementation
- Memory: Recommendation for BlueStore OSDs are 3 GB of memory for every HDD OSD and 5 GB for an SSD OSD. In truth, there there are the number of variables that lead to this recommendation, but suffice to say that you never want to find yourself in the situation where your OSDs are running low on memory and any excess memory will be used to improve performance. Aside from the base-line memory usage of OSD, the main variable affecting memory usage is the number of PGs running on the OSD. While total size of data size does have an impact on memory usage, it is dwarfed by the effect of the number of PGs. A healthy cluster running within the recommendation of 200 PGs per OSD will probably use less than 4 GB of RAM per OSD.
- CPU: Recommendation is 1 GHz of CPU power per OSD. The CPU is only used when there is something to be done. if there is no I/O, then there no CPU is needed. this, however , scales the other way: the more I/O, the more CPU is required. To Complicate things further, the CPU requirements vary depending on I/O size as well, with larger I/O requiring more CPU. If the OSD node starts to struggle for CPU resources, it can cause OSDs to start timing out and getting marked out from the cluster, often to rejoin several seconds later. This continuous loss and recovery tends to place more strain on the already limited CPU resources, causing cascading failures.
- DISKs: When choosing the disks to build a Ceph cluster with, there is always the temptation to go with the biggest disks you can, as the total cost of ownership figures looks great on paper. Unfortunately, in reality this is often not a great choice. While disks have dramatically increased in capacity over the last 20 years, their performance hasn't.
7.2k disks = 70–80 4k IOPS
10k disks = 120–150 4k IOPS
15k disks = you should be using SSDs
As a general rule, if you are designing a cluster that will offer active workloads rather than bulk inactive/archive storage, then you should design for required IOPS and not capacity. If your cluster will largely contain spinning disks with the intention of providing storage for an active workload, then you should prefer an increased number of smaller capacity disks rather than the use of larger disks.
- Do use 10 G networking as a minimum
- Do research and test the correctly sized hardware you wish to use
- Don’t use the no barrier mount option with filestore
- Don’t configure pools with a size of two or a min_size of one
- Don’t use consumer SSDs in production environments
- Don’t use raid controllers in write back mode without battery protection
- Don’t use configuration options you don't understand
- Do carry out power-less testing
- Do have an agreed backup and recovery plan
- At least three monitors are normally required for redundancy and high availability
- At least two managers are normally required for redundancy and high availability
- At least 3 Ceph OSDs are normally required for redundancy and high availability
- Ceph Block Devices and Ceph Object Storage do not use MDS
where all this information is summarized together with pointers to the: Mastering Ceph Book, Official Ceph Documentation, myself and also:
